
Parsing and editing HTML in Dart | Web scraping in Dart
During the last few months, I’ve been quietly building yet another side project.
In one component of that side project, I needed to take in some HTML, change some things, and return slightly different HTML.
“I’ll just slap together some incomprehensible regex… and voilà! That wasn’t hard at all!”
If you’ve ever gone on StackOverflow to find, or god forbid, ask for the one HTML regex to rule them all, somebody will tell you quite quickly that it isn’t such a great idea.
Since HTML is far from a regular language, parsing it with regular expressions can be full of weird edge cases. The nice thing is that proper HTML parsers handle the edge cases for you.
As an added benefit, using a proper HTML parser is also simpler than hacking together some messy regular expressions.
The Hello World
Given Dart’s history, it has a quite solid toolbox for working with all things Javascript, the DOM, CSS and, you guessed it, parsing HTML.
To get started, all we need to do is to add package:html to our pubspec file:
dependencies:
html: # check pub.dev for latest version
It’s time to parse some good old HTML.
import 'package:html/parser.dart' as html_parser;
void main() {
final document = html_parser.parseFragment('''
<p><a href="https://dart.dev">Dart</a></p>
<p><a href="https://flutter.dev">Flutter</a></p>
''');
final anchors = document.querySelectorAll('a');
for (final anchor in anchors) {
final href = anchor.attributes['href'];
print('${anchor.text} - $href');
}
}
That would print out the following:
Dart - https://dart.dev
Flutter - https://flutter.dev
Since we’re parsing some HTML, but not a whole web page, we used parseFragment. If we were parsing a whole webpage, we’d use the parse method instead.
The parseFragment the method gives us a DOM tree that kinda looks like this:
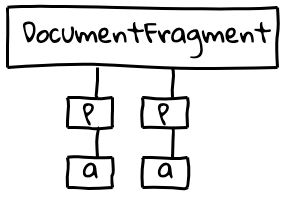
The resulting DOM tree from parsing the HTML text input.
For simple cases, we can just use the .querySelector() method on the document. This works when we want to find all the <a> elements on a page or something equally simple.
But if we’re building something more complex, like a pretty printer for HTML code, chances are we need to iterate over the list of nodes, and then use some recursion in order to process every single nested element. We’ll have examples of this later.
Displaying top 10 Google search results
Let’s imagine we want to get the top 10 Google search results for the query flutter blogs and print them to the console.
Easy-peasy.
import 'package:html/parser.dart' as html_parser;
import 'package:http/http.dart' as http;
void main() async {
// Fetch Google search results for "flutter blogs".
final response = await http
.get(Uri.parse('https://www.google.com/search?q=flutter+blogs'));
final document = html_parser.parse(response.body);
// Google has the best class names.
final results = document.getElementsByClassName('BNeawe vvjwJb AP7Wnd');
print('Top 10 results for "flutter blogs":\n\n');
var placement = 1;
for (final result in results) {
print('#$placement: ${result.text}');
placement++;
}
}
That should print this:
Top 10 results for "flutter blogs":
#1: Flutter – Medium
#2: Flutter Blog by GeekyAnts – The GeekyAnts Blog
#3: Flutter Blogs (@FlutterBlogs) | Twitter
#4: Blogs Archive - FlutterDevs - Why Flutter?
#5: Guest Blog: Flutter Trends and Community Updates | Syncfusion Blogs
#6: The top 45 must-follow Flutter experts on Twitter - Codemagic blog
#7: iiro.dev | Dart and Flutter tutorials, articles, tips and tricks ...
#8: Flutter Blog Engine | ButterCMS
#9: Top Apps Made with Flutter – 17 Stories by Developers and ...
#10: Flutter vs React Native: A Developer's Perspective - Nevercode
I don’t know about the other ones, but #7 on that list is total garbage.
I’m not placing that high on search results anymore - I guess I should write more articles.
Editing the parsed DOM tree
As the DOM tree is a nested structure of Dart objects, we can also easily modify it on the fly.
Let’s imagine we’re building a comment system in Dart.
Among other things, such as disallowing malicious HTML and sanitizing other content, we probably want to handle the links.
We’ll want to:
- open all links in a new window
- tell search engines (such as Google) to not give these links credit in search engine rankings.
The way to do it is to add rel="external nofollow" and target="_blank" to each <a> element.
This is one way to do it:
import 'package:html/parser.dart' as html_parser;
void main() {
final document = html_parser.parseFragment('''
<p>Nice blog post! I also wrote about the same thing on my blog,
<a href="https://example.com">check it out</a>!</p>
''');
// Find all anchor ("<a>") elements in the parsed document.
final anchors = document.querySelectorAll('a');
for (final anchor in anchors) {
// Iterate over all <a> elements and add these attributes
// to each one.
anchor.attributes.addAll({
'target': '_blank',
'rel': 'nofollow',
});
}
print(document.outerHtml);
}
That should print the following:
<p>Nice blog post! I also wrote about the same thing on my blog,
<a href="https://example.com" target="_blank" rel="nofollow">check it out</a>!</p>
Allowing only specific HTML tags
Remember how I told you there are two ways to process the DOM tree, the simple way, and the less simple way?
It’s time to learn the less simple way. But there’s no reason to worry - it’s not too hard!
Maybe we’re building a comment form, and only want to allow bold, italics, and underline text?
Easy peasy:
import 'dart:convert';
import 'package:html/dom.dart';
import 'package:html/parser.dart' as html_parser;
import 'package:meta/meta.dart';
final _htmlEscape = HtmlEscape(HtmlEscapeMode.element);
class LimitedHtml {
LimitedHtml({required this.allowedTagNames});
final Set<String> allowedTagNames;
String filter(String html) {
final buffer = StringBuffer();
final document = html_parser.parseFragment(html);
_visitNodes(buffer, document.nodes);
return buffer.toString().trim();
}
void _visitNodes(StringSink sink, List<Node> nodes) {
for (final node in nodes) {
if (node is Element) {
_visitElement(sink, node);
} else if (node is Text) {
sink.write(_htmlEscape.convert(node.text));
}
}
}
void _visitElement(StringSink sink, Element element) {
final tag = element.localName!.toLowerCase();
if (allowedTagNames.contains(tag)) {
sink.write('<$tag>');
_visitNodes(sink, element.nodes);
sink.write('</$tag>');
} else {
sink.write(element.text);
}
}
}
In just roughly 30 lines, we built a reusable class that takes in a list of allowedTagNames and ignores everything else.
Let’s try it in action:
void main() {
final html = '''
<p>I can't <u>underline</u> enough how <b>bold</b> and <i>italic</i> night it was!</p>
<div>
<a href="javascript:doSomethingBad()">Click me please!</a>
</div>
''';
final limitedHtml = LimitedHtml(allowedTagNames: {'p', 'b', 'i', 'u'});
print(limitedHtml.filter(html));
}
That would print the following:
<p>I can't <u>underline</u> enough how <b>bold</b> and <i>italic</i> night it was!</p>
Click me please!
Because the DOM tree can in theory nest infinitely, we have to use some recursion. It’s always a bit weird to wrap your head around it, but thankfully this is one, not the worst kind to understand.
We’re also using a StringBuffer. You can think of it as an efficient way for combining a lot of strings into one string.
In the case of a small number of strings, it’s not needed. But if we don’t know how many strings we need to combine and there might be a lot of them, StringBuffer is a good choice.
Converting HTML to Markdown
There are a lot of Markdown to HTML converters, but what about going the other way?
import 'dart:convert';
import 'package:html/dom.dart';
import 'package:html/parser.dart' as html_parser;
final _htmlEscape = HtmlEscape(HtmlEscapeMode.element);
class HtmlToMarkdown {
String convert(String html) {
final buffer = StringBuffer();
final document = html_parser.parseFragment(html);
_visitNodes(buffer, document.nodes);
return buffer.toString().trim();
}
void _visitNodes(StringSink sink, List<Node> nodes) {
for (final node in nodes) {
if (node is Element) {
_visitElement(sink, node);
} else if (node is Text) {
sink.write(_htmlEscape.convert(node.text.trim()));
}
}
}
void _visitElement(StringSink sink, Element element) {
final tag = element.localName!.toLowerCase();
switch (tag) {
case 'p':
sink.writeln();
sink.writeln();
_visitNodes(sink, element.nodes);
break;
case 'strong':
sink.write(' **');
_visitNodes(sink, element.nodes);
sink.write('** ');
break;
case 'em':
sink.write(' _');
_visitNodes(sink, element.nodes);
sink.write('_ ');
break;
default:
_visitNodes(sink, element.nodes);
break;
}
}
}
It’s far from complete, but it’s good enough for a limited sample.
Let’s try it. This:
void main() {
final html = '''
<p>Hello <strong>there</strong> world!</p>
<p>Have a <em>lovely</em> day!</p>
''';
print(HtmlToMarkdown().convert(html));
}
prints the following:
Hello **there** world!
It's quite a _lovely_ day!
Not too bad considering it's just 50 lines of code.